
Spark UIを使ったパフォーマンスの分析と改善
前回記事の処理を分析して並列性能をアップ
今回はeQTLの全データをDataFrameにする予定でしたが、前回記事に改善箇所がありましたのでSparkのUIとともにその解説をしたいと思います。
時間がかかっていそうな箇所
時間がかかっていたのはこの部分です。

前回の処理
これはgzipされたファイルを指定したDataFrameへの読み込み処理ですが、ダウンロードしたeQTLデータのファイルをそのまま使っていました。
ダウンロードしたファイルはgzipです。
この普通のgzipファイルでも複数のパーティションに分かれるようにするために、
Spark起動時にpackagesとしてnl.basjes.hadoop:splittablegzip:1.3を、そして読み込み時に
.option('io.compression.codecs', 'nl.basjes.hadoop.io.compress.SplittableGzipCodec')\
を指定していました。 DataFrame.getNumPartitions()でパーティションの数を取得できるのですが、次のように複数のパーティションが作られていることがわかります。 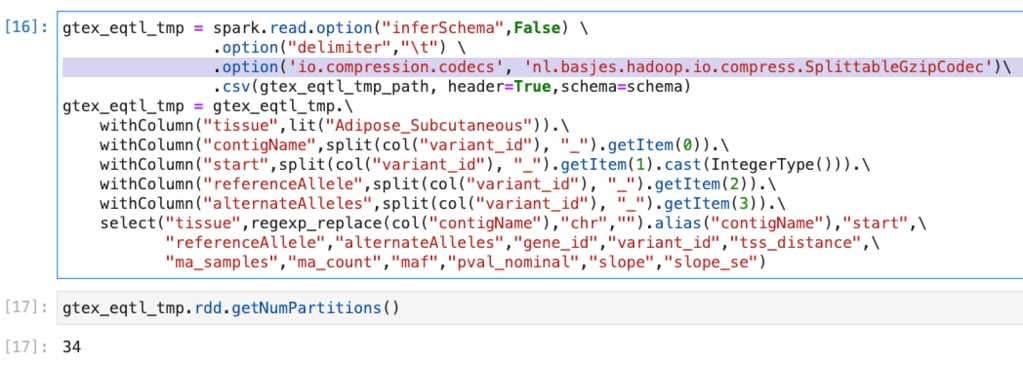 (ちなみに何も指定しないと、次のようにパーティションが1つしかできません。)
(ちなみに何も指定しないと、次のようにパーティションが1つしかできません。)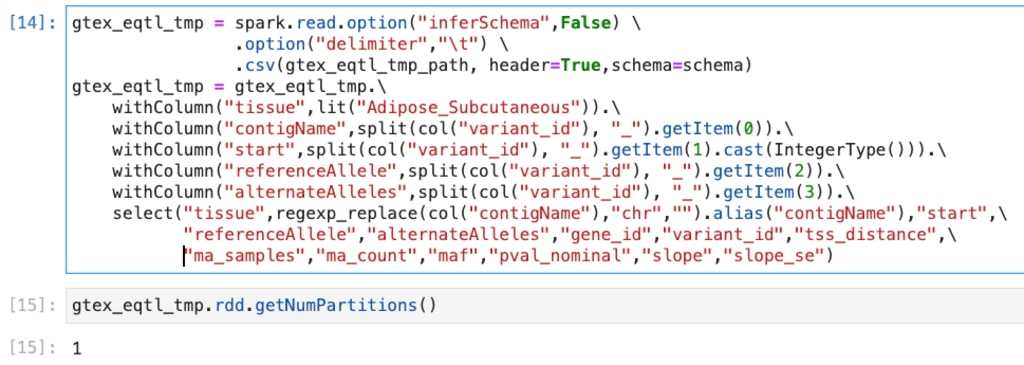 このようにパーティションは別れているので良さそうですが、処理するファイルサイズの割に時間がかかっている気がします。 この段階では数分の処理なので気にならないように思うかもしれないですが、これはAdipose_Subcutaneousのみなので、およそ50のtissueを処理することを考えると無視できません。 データが小さいこともあり前回はmacで動かしたSpark上で動作させていたのですが、テスト用のSpark Clusetrに載せて気づいたのが今回の話というわけです。
このようにパーティションは別れているので良さそうですが、処理するファイルサイズの割に時間がかかっている気がします。 この段階では数分の処理なので気にならないように思うかもしれないですが、これはAdipose_Subcutaneousのみなので、およそ50のtissueを処理することを考えると無視できません。 データが小さいこともあり前回はmacで動かしたSpark上で動作させていたのですが、テスト用のSpark Clusetrに載せて気づいたのが今回の話というわけです。
処理時間
前回のAdipose_Subcutaneous.allpairs.txt.gzに対する処理をcpu数を変えて実行してみると、次のように途中から並列性能が落ちることがわかります。
これではSparkのメリットを享受できていないようにみえます。 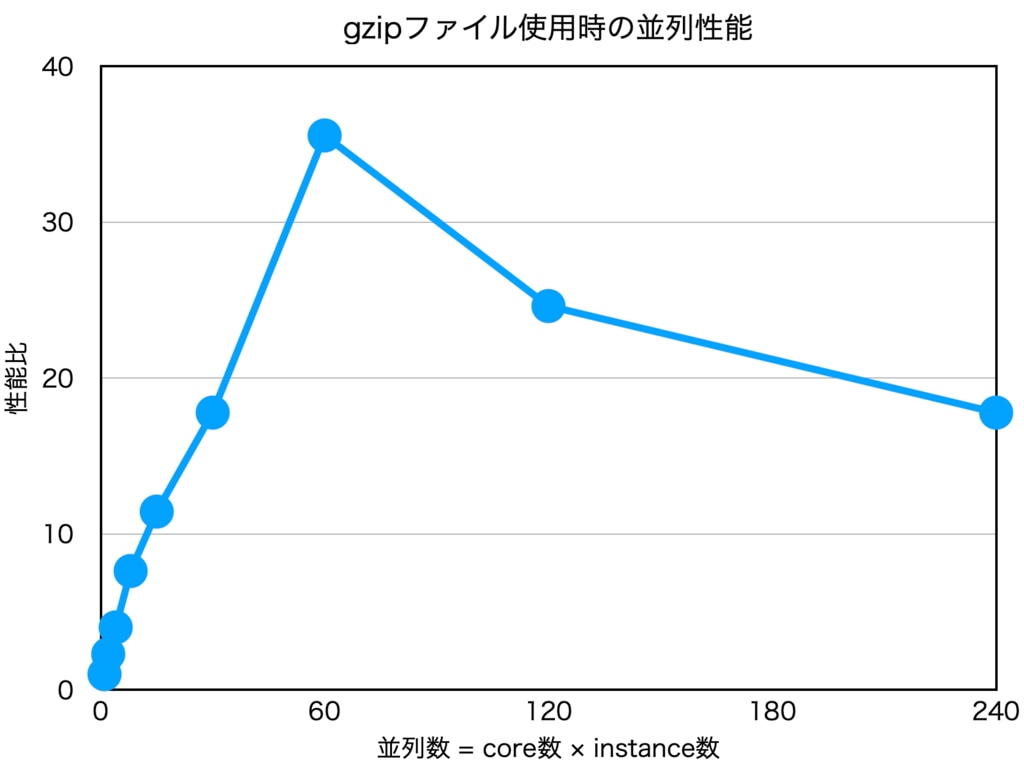
(並列数1のときを1とした性能の比をとっています)
Spark UIを使った分析
Spark UIを使うと時間のかかている箇所を簡単に見つけることができます。SparkのJobやStage、Taskなどの情報をわかりやすく得ることができます。
Spark UIはDriverが動いているマシンのポート4040番あるいはそれ以降に起動され、アクセスすると次のような画面が表示されます。 Spark UIではStageの情報を詳しく確認できます。実際に並列数を変えて実行して確認すると、以下のグラフのように、なんと並列数を増やせば増やすほど読み込みのデータが増えていることがわかります。これは危ない。 仮にUS Regionに置かれた課金ありのデータであれば、並列数の分だけ料金がかかってしまう動きですし、いかにも性能が出なさそうです。
Spark UIではStageの情報を詳しく確認できます。実際に並列数を変えて実行して確認すると、以下のグラフのように、なんと並列数を増やせば増やすほど読み込みのデータが増えていることがわかります。これは危ない。 仮にUS Regionに置かれた課金ありのデータであれば、並列数の分だけ料金がかかってしまう動きですし、いかにも性能が出なさそうです。 
ファイルは4.2GBなのですが、240並列で何と511.4GBも読み込みしています。 もう少し詳しく見てみると次の図のようにstage内のtaskが後半になるに従いinputの量が増えていることがわかりました。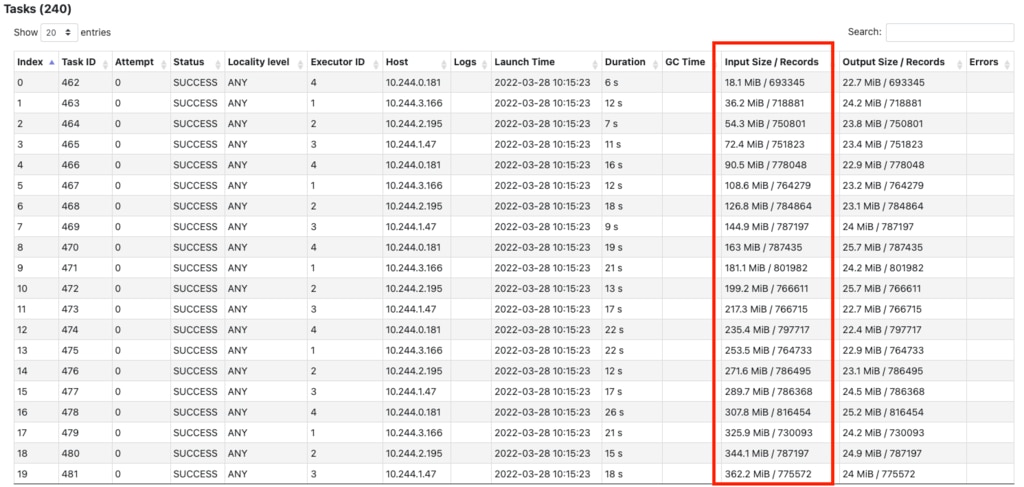
( 240個にわかれたtaskの最初の20個)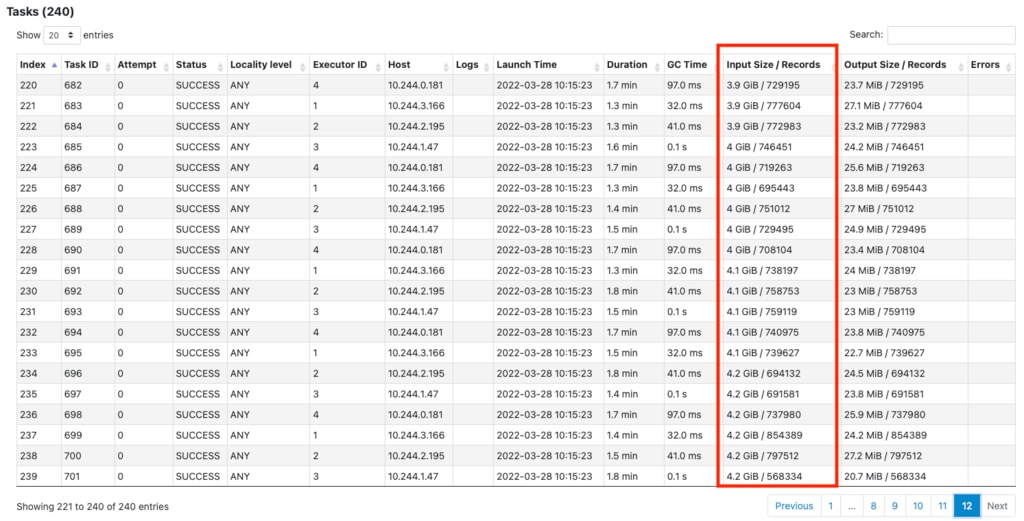
( 240個にわかれたtaskの最後の20個)
240個に分割され、18.1MBから始まって最後は4.2GBです。これはおそらく先頭から解凍し、必要なデータが得られたところで停止する、という動きかと推測できます。input sizeの総和は次の式になると思われ、端数もあるのでピッタリではありませんが概ね一致しています。
解決方法
この問題は、ファイル形式をgzipではなくbgzipにすることで解決できました。 bgzip形式は"Blocked GNU Zip Format"です。
通常のgzipファイルはファイルを連続して圧縮していて、実は途中から解凍できなかったりしますが、bgzipはBlockごとに分割されているため、ファイルの途中にある箇所のみを解凍することができる特徴を持っています。 bgzipファイルはSpark起動時に次のオプションを入れておくことで利用可能になります。
また、gzipで使っていたcodec指定を外す必要もあります。 
bgzipされたファイルで同様のテストを行った結果、小さなinputで済みました。
以下のように並列数が増えてもinputのデータ量は増えていないことがわかります。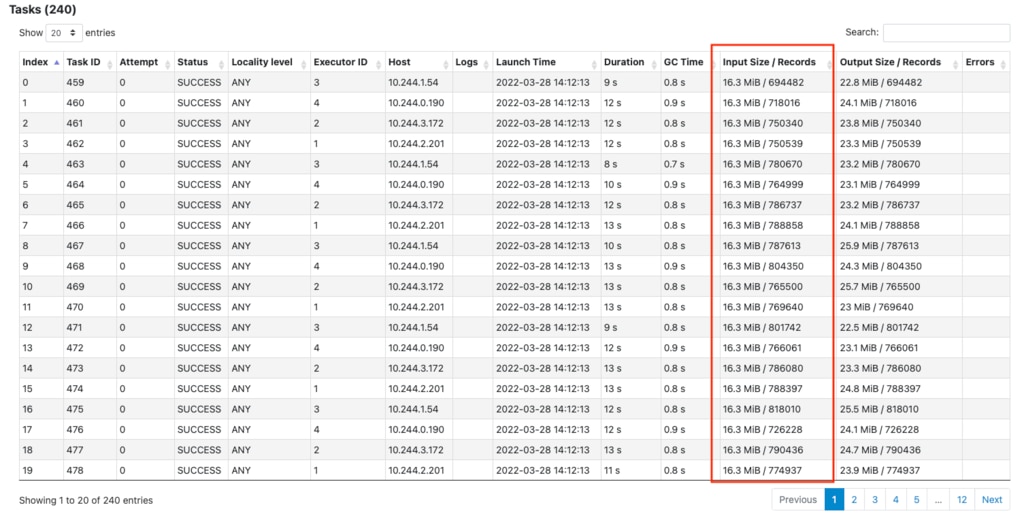
( 240個にわかれたtaskの最初の20個)
( 240個にわかれたtaskの最後の20個)
結果
これによってこのステージにかかる時間は次のグラフのように高速になりました。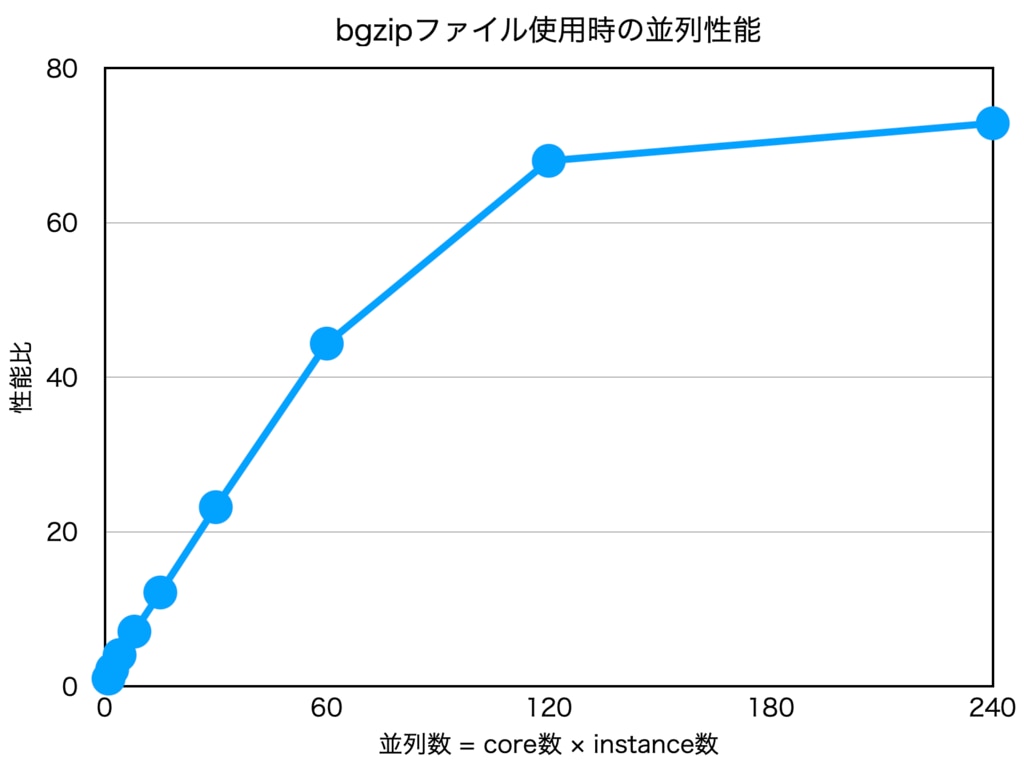
データが小さいのもあり120から240への伸びはそれほどではありませんが、かなり改善できました !
これで次回は効率良くデータ変換を行えそうですね。次回は今度こそeQTLデータの全tissueをDataFrameに取り込みます。

