
Takeru Core DC は、コアファシリティに計算資源や人的リソースを集約するにあたって起こり得るITシステム面の問題を解決するための、柔軟性に富んだ共用計算プラットフォームです。ニーズや環境の変化が激しいデータ解析周りのITインフラ面、また、所属やユースケースが異なるユーザーに対する管理面などの課題に対応し、よりセキュアな環境における解析を可能とします。
Issues
コアファシリティの課題
いち研究室より多くのユーザーを抱えるコアファシリティに適した計算システムの構成として、まず、研究室にて使用しているクラスタ型計算サーバーの規模をそのまま大きくすれば、リソース面では問題ないように見えます。しかし、コアファシリティが共用・多施設共同で利用される点を踏まえて考えると、この「研究室で使っていたクラスタシステム」拡大版では問題が生じます。
データ解析環境の多様化
様々なデータや解析手法が出てきて、それぞれにシステム要件が異なる。ex. クラスタではOSを自由に選択できない
分離性
様々なユーザが存在するため、
データへのアクセスやリソースを
適切に制限しなければならない
セキュリティ
外部からの不正アクセスに備え、
OSやネットワーク機器をアップデートし続けなければならない

管理コストの増加
これらのことを考慮したシステムには、クラスタシステムとは異なるスキルが管理者に求められる。当然、管理に要する時間も増える

Images by Freepik
Service
解決策
Takeru Core DC
共用計算プラットフォームとして、クラウド技術OpenStackで"プライベートクラウド"を構築·
システムご導入後の活用や拡張を長期にわたりサポート
コアファシリティ管理者が必要とするサポートレベルに応じた、段階的なサポートメニューを提供
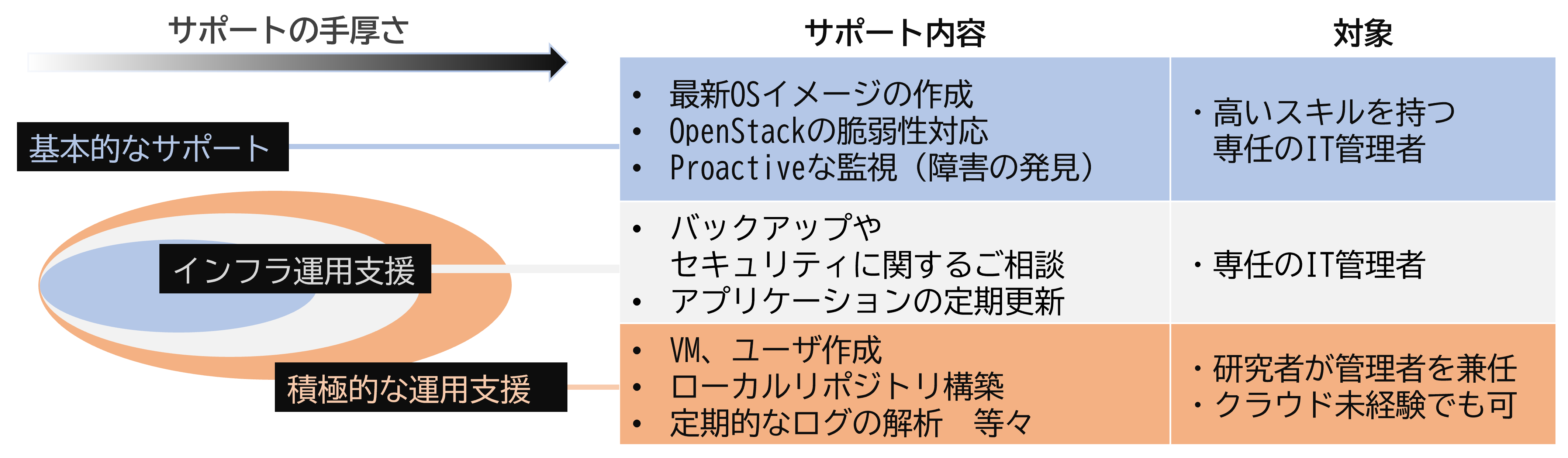
※計算機システムとしてのハードウェア仕様構成は、ナベ インターナショナルのTakeruシリーズを基本として、コアファシリティの状況やご希望を伺いながら提案・協議のうえ、決定いたします。
Usage examples
活用例
ナベ インターナショナルは長年、Takeruシリーズを多数ご導入いただく中で、計算機・ストレージ、データ解析システムの面からバイオインフォマティクス研究の潮流を追ってきました。近年の、分析・計測機器の進化による取得可能データの増大や、機械学習・人工知能の隆盛をはじめとする研究手法の新展開は、当然ながら計算機システムの進化を促進しています。さらにここに、本ウェブページ冒頭に述べた状況が加わり、従来は情報解析依頼元であった実験系研究者の方々を直接の計算機ユーザーとして多数抱える、「コアファシリティが提供するデータ解析プラットフォーム」構築のご相談が増えています。
色々とお話を伺うと、コアファシリティ向けシステムにおける「概念としての課題」は大まかに共通しているため、枠組みとしてのTakeru Core DCが課題解決に存分に寄与するものと考えております。一方、具体的に何を構築するか詳細の詰めにおいては、個別の状況に即したカスタムの提案が必要になりますが、そこを一緒に検討していく段階もTakeru Core DCの一部といえます。ご導入システムの責任者・管理者となる方が課題やご希望を明確にするにあたり、以下の事例・活用例や目指す将来像が一助となれば幸いです(詳細はダウンロード資料にてご参照いただけます)。
| 01 |
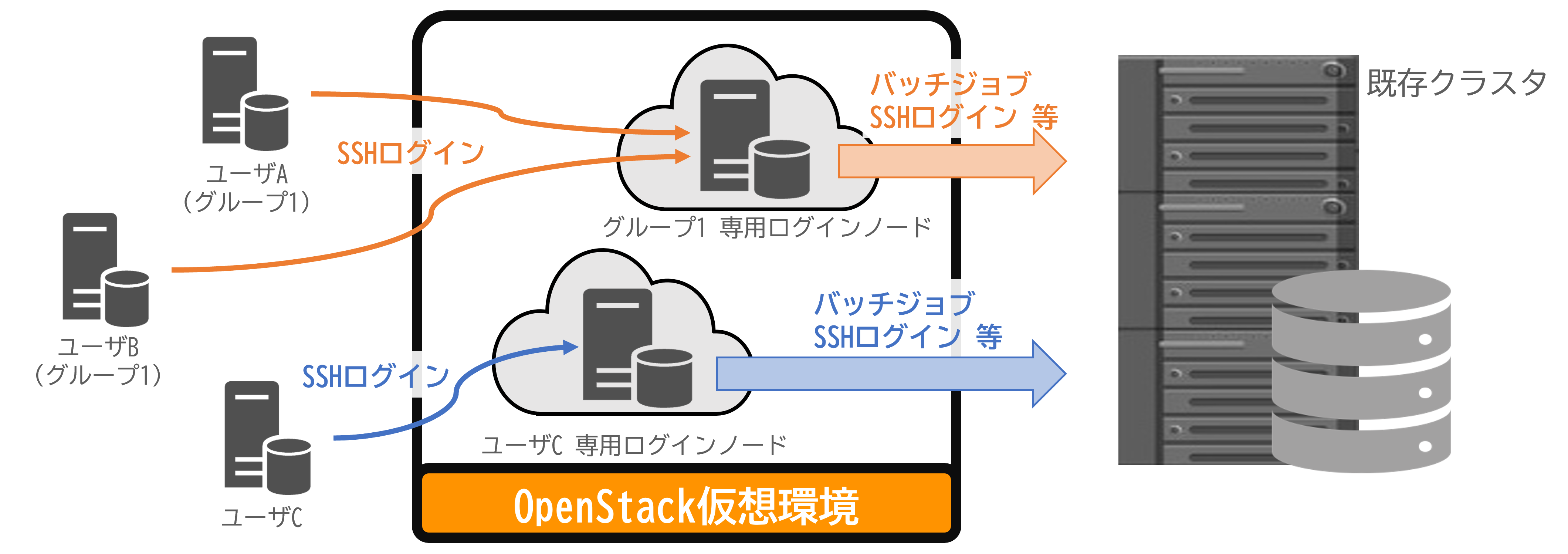
ログインノード仮想化
既存クラスタシステムのログインノードを仮想化し、ユーザ毎、グループ毎の専用ログインノードを構築することで、分離性を高める。
※他人(他グループ)のユーザー名やデータはもちろん、プロセスも見えなくなる。
| 02 |
組織内システム仮想化
同一研究組織や同一企業内で運用する、用途やデータ運用ポリシーの異なる複数のシステム(例えば、基幹系サーバー・開発サーバー・顧客環境再現検証用テストサーバー)を、分離性を確保したまま1つのシステム内に構築する。
| 03 |
コアファシリティ化
複数組織(研究機関、企業などの単位)の計算コアとして、異なる研究用途向けにそれぞれ計算環境を提供する大規模システムを構築する。
| 04 |
エッジデータセンター
研究機関と大規模病院・臨床検査機関を結び、地域の組織や患者・健康な個人のデータを集約するデータセンターを構築する。
Case studies
導入事例

最新の計算サーバーシステムで
幹細胞の創薬応用と再生医療応用を推進する
Presentations
解説資料
2024年10月に沖縄県那覇市にて開催された1st Asia & Pacific Bioinformatics Joint Conference(APBJC 2024)において、ナベ インターナショナルがスポンサードセッションにて講演した際の資料(英文のみ)です。
Takeruを安定的、継続的に運用するための定期更新サービスもご用意しております。
