Dear GATK4 !
今年に入り、GATK4.0が発表されました。
これまでと大きく異なる点がいくつもある、ビッグニュースでした。
まずはライセンスが大幅に変わっています。これまでアカデミックでしか無償利用ができなかったのですが、BSD 3-clauseライセンスになり、Commercial useが許可されています。
次に、GATK4に内包されるツールが拡大し、機能アップ、
さらに、並列分散処理基盤であるApache Sparkに対応してきました。
ツールの中にはHaplotypeCallerSparkやBwaSparkといったものがあり、
ツール名が示す通りSparkの力を使ってmappingからvariant callingをカバーし、高速化しようとしていることがわかります。
Sparkによる高速化
Apache Sparkは大規模データ処理のための分析エンジンで、hadoopのhdfsあるいはその他のコンポーネントと共に利用します。
Sparkそのものの特徴としては中間データを途中でディスクに書き出したりしないことによる高速化などが挙げられますが、
NGSデータの分野にとっては、そもそもそれ以前にデータをhadoop hdfs上に持つことからして大きな変化と思われます。
hadoop hdfsはデータの持ち方がこれまでと大きく変わります。
データやデータ群を複数の計算ノードにあるローカルディスクに分散して持たせ、
どの計算機からも分散処理ができるようにアクセスすることができます。
分散と同時に重複して持たせることができ、分散による高速処理と耐障害性とを同時に満たしつつ、
高い拡張性を持っていることが特徴です。
従来であれば高価な共有ディスクを使っていたような局面でも、比較的安価なローカルディスクでその性能を超えることができるというものです。
また、インメモリーで処理ができることも見逃せないポイントのひとつです。
1TBものメインメモリを積むことがDual Socketのサーバーでも当たり前にできるようになりましたが、
そうしたサーバーを複数持つことでかなり大きなデータをメモリに納めて計算することができるため、
これまでの常識ではできないと思っていた処理が可能になり、ゲノムデータや医用画像、顕微鏡などの巨大なデータから新たな知見が導き出されることを期待せずにはいられません。
GATK4+Sparkについて(2018年5月時点)
まず、ひとつだけ注意しなければならないのはまだBeta版のツールが多いということです。
gatk --list
で使用可能なツールが表示されるのですが、Spark対応のものは軒並み「Beta」バージョンです。
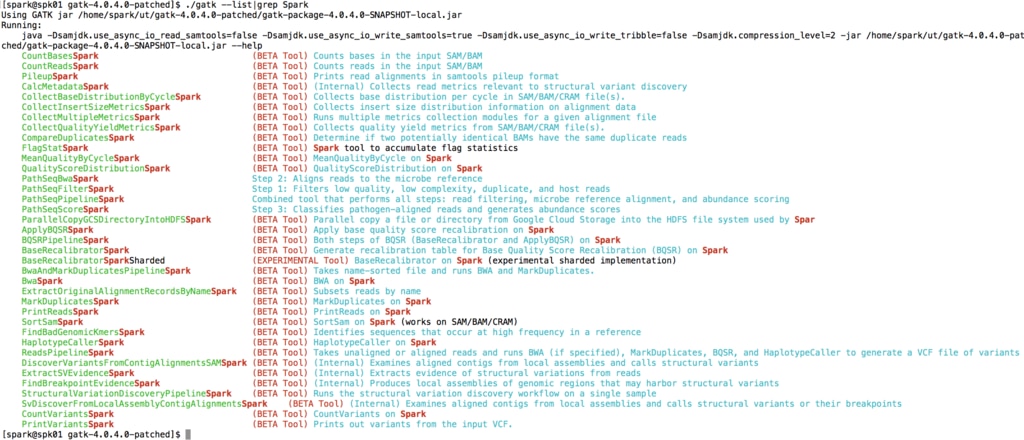
この点はいずれ正式リリースがなされることと思われるのでその前提で、試しにHaplotypeCallerSparkを動作させてみました。
結果、数台の試験機にvariant callingの処理が分散実行され、高速化に期待が持てることがわかりましたが、
バグによりまだ結果が安定していないことも確認されました。

Beta版なので当然といえば当然で、この点は正式リリースに期待しましょう。

実際、バグレポートはすでにあがっていて、パッチをあてることで改善できることも確認できています。
まとめ
今回はGATK4やSparkのお話をしましたがいかがでしたでしょうか。
GATKはとても人気の高いソフトウェアのひとつで、使っている方も多いと思います。
大きな変化が出てきていますので、ぜひ注目して情報収集や試験導入をしていく必要がありそうです。
まだBetaバージョンの段階のものが多いですが、いずれ正式リリースされていくはずです。
NABEでも引き続きウォッチングしていく領域ですので、ご関心ある方はご相談やお話の共有をしていければと思います。

